LTAP: what if OLTP and OLAP meet at storage?
I read Databricks' article on Lakebase and LTAP, and the part that stayed with me was not the product announcement.
It was the design choice.
Instead of asking one engine to be good at both OLTP and OLAP, the article asks a different question: what if the engines stay separate, but the storage becomes the common layer?
That was the small click for me. I usually think of OLTP systems as the place where application truth lives, and OLAP systems as the place where copied, reshaped, query-friendly truth lives. This article made me pause and ask whether that boundary is going to move.
In this note, I want to keep the main idea simple, explain why it feels important, and then sit with the questions I still have.
The article in one idea
OLTP means online transaction processing. Think application databases: orders, payments, users, inventory, subscriptions. These systems care about small reads and writes, correctness, transactions, and ACID guarantees.
OLAP means online analytical processing. Think dashboards, aggregations, reporting, model features, and large scans over many rows. These systems care about reading a lot of data efficiently.
Traditionally, we keep these worlds separate.
The application writes to Postgres or MySQL. Then some CDC or ETL pipeline copies changes into a warehouse or lakehouse. The analytical system gets a second copy of the data, usually in a format that is better for scans.
The Databricks article argues for a different shape. Lakebase separates the Postgres compute layer from the storage layer. The write-ahead log moves into a service called SafeKeeper. The data pages move into a service called PageServer. The durable data sits in object storage.
Then LTAP takes the next step: if the durable data is already in the lake, can analytical engines read the same data without waiting for a separate CDC pipeline?
That is the interesting bit.
The line that clicked
The cleanest way I understood the article is this:
- HTAP: one engine tries to handle transactions and analytics together.
- LTAP: different engines handle different workloads, but meet at the storage layer.
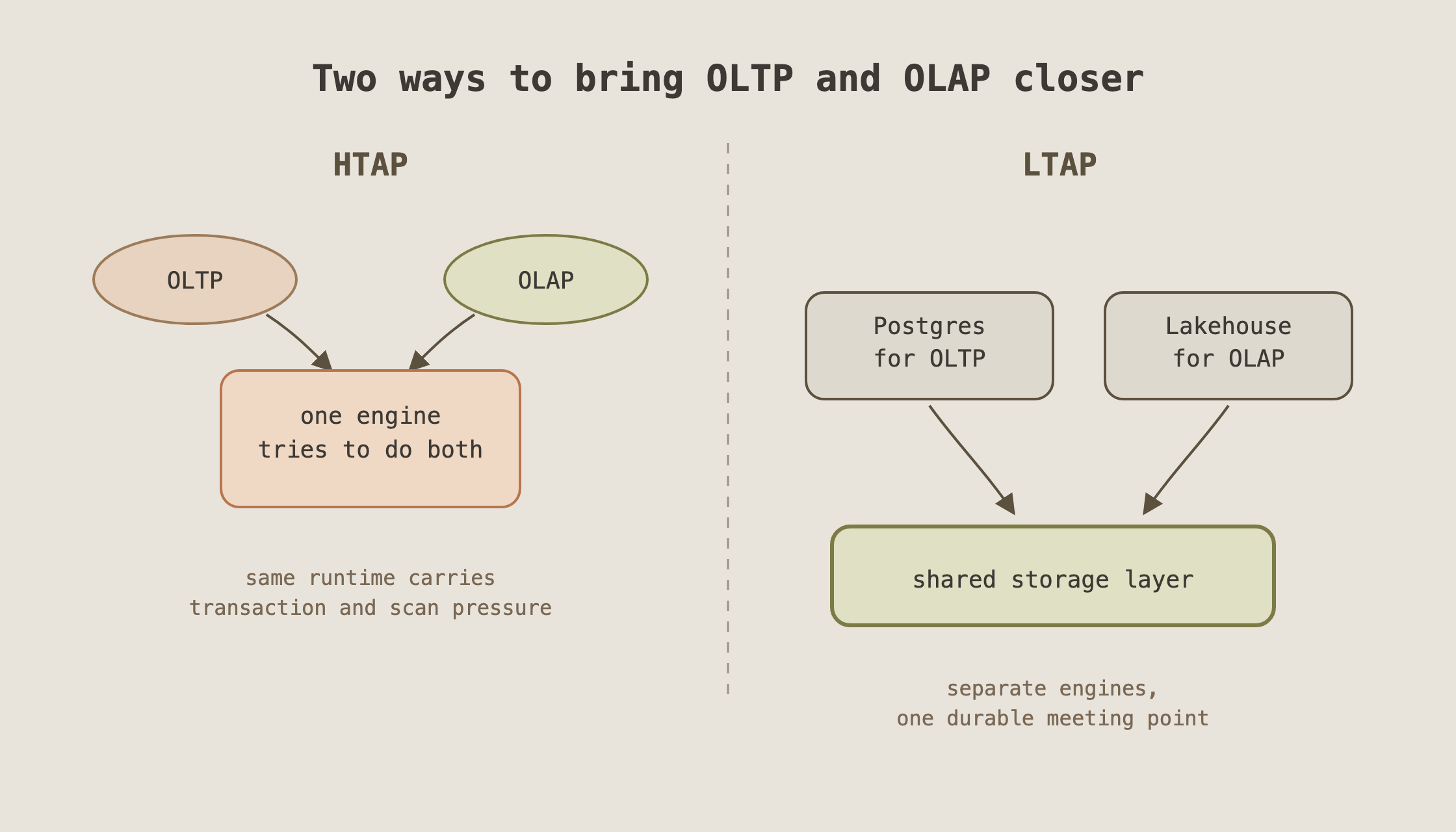
This is a subtle difference, but it matters.
Transactions and analytics want different things from an engine. A transaction engine wants fast point lookups, indexes, isolation, and predictable latency. An analytics engine wants columnar reads, parallel scans, compression, and big aggregations.
Trying to make one engine excellent at both sounds elegant, but also heavy. You are asking one system to carry two different personalities.
The LTAP idea feels more practical: let Postgres keep being Postgres for transactional work, let lakehouse engines keep being good at analytical work, and make the storage layer the place where the two worlds connect.
Why this feels like a shift
The reason this caught my attention is that it sounds similar to what happened with the lakehouse.
Data warehouses used to feel like the center of analytical truth. Then object storage, Parquet, Delta, Iceberg, and lakehouse engines changed the question. Instead of asking, "Which warehouse owns this data?", people started asking, "Can the data live in an open storage layer and be queried by different engines?"
This article made me wonder if something similar could happen to OLTP.
Today, we often assume the operational database owns the durable truth tightly. If analytics needs that truth, we copy it out. We mirror it. We build CDC jobs. We debug lag. We explain why one table exists in the warehouse and another does not.
But if the operational database itself is built over a lake-like storage layer, the question changes.
- Fewer copies: analytics may not need a separate mirrored table for every operational table.
- Less pipeline work: the freshness problem may move from CDC jobs into the database storage architecture.
- Better isolation: transactional compute and analytical compute can scale separately.
- Easier branching: database clones and recovery can become metadata operations instead of full physical copies.
I am intentionally saying "may" here. The idea is strong, but the real test is in the details.
The part I am still skeptical about
My first skeptical reaction was around ACID.
OLTP databases are trusted because they protect the boring but important things: committed writes should not disappear, transactions should not observe nonsense, and the database should recover correctly after failure.
So for me, the hard question is not "can analytical engines read Parquet?"
Of course they can.
The harder question is: can a system keep the storage unified while still preserving the transactional behavior people expect from Postgres?
The Databricks article says Lakebase handles this by separating the log and page storage. Writes become durable through SafeKeeper. Pages are materialized through PageServer. LTAP then stores data in open columnar formats while preserving Postgres semantics, including type details and multi-version behavior.
That is the part I want to understand more deeply. Not because I think it is impossible, but because this is where the architecture earns trust or loses it.
Questions I am still carrying
The first question is about history.
In many analytics systems, CDC is not only used to make a current copy of a table. It is also used to build history. A slowly changing dimension table, for example, can show that a user's email, plan, region, or account owner changed over time.
If LTAP gives us fresh access to operational tables, what replaces that modeling pattern?
My current guess is: LTAP can reduce the need for copying current state, but it does not automatically remove the need to model business history. Table snapshots and time travel are useful, but they are not the same as a carefully designed SCD Type 2 table with valid_from and valid_to columns.
Maybe the future pattern is that more history is modeled directly in the operational database. Maybe analytical engines query storage snapshots for some cases. Maybe teams still build explicit history tables, just with less fragile movement underneath.
I do not have a clean answer yet.
The second question is query performance.
The article's answer is that most analytical data can be read from columnar files in object storage, while only very recent changes need to be merged from PageServer. That makes sense as a shape. Columnar files are good for analytics, and caches can hide a lot of latency.
But I still want to see how it behaves under real workloads.
- What happens when a query scans a very large operational table?
- How much object-storage bandwidth does that consume?
- How often does the analytical engine need to merge recent changes?
- What are the workloads where this performs beautifully, and what are the workloads where the old copy-to-warehouse model is still simpler?
Those are not objections. They are the next questions I would ask before treating LTAP as a default architecture.
Where I am landing
The most interesting idea in the article is not that Postgres data can eventually show up as Parquet.
The interesting idea is that the ownership boundary may move.
Instead of an operational database owning storage and analytics receiving a copied version later, the storage layer itself could become the shared foundation. Postgres remains the transactional engine. Lakehouse engines remain the analytical engines. The durable data underneath becomes the meeting point.
That feels like a meaningful idea to watch.
If the lakehouse changed the way we think about warehouses, LTAP might be an early sign of a similar shift for operational databases. I am not fully convinced yet, especially around history modeling and performance in messy workloads, but I understand why the direction is exciting.